Microsoft Dynamics 365: Finance and Operations Apps Developer Exam (MB-500) - Microsoft Exam Questions
Last updated on June 22, 2026
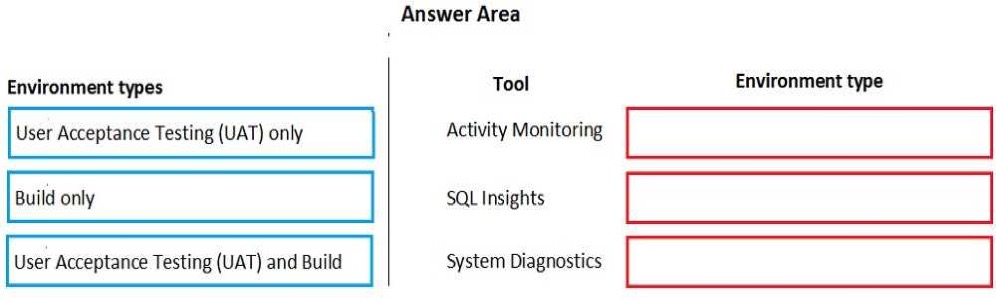
Which two filtering types can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
to join the discussion
No discussions yet. Be the first to ask!
Delete Comment
Are you sure? This action cannot be undone.
You need to create the extension in the Application Object Tree (AOT) and add the extension to the demoExtensions model. Solution: Add a new form object to the project and name the form SalesTable.Extension. Does the solution meet the goal?
to join the discussion
No discussions yet. Be the first to ask!
Delete Comment
Are you sure? This action cannot be undone.
Solution: You create the following code:

Does the solution meet the goal?
to join the discussion
No discussions yet. Be the first to ask!
Delete Comment
Are you sure? This action cannot be undone.
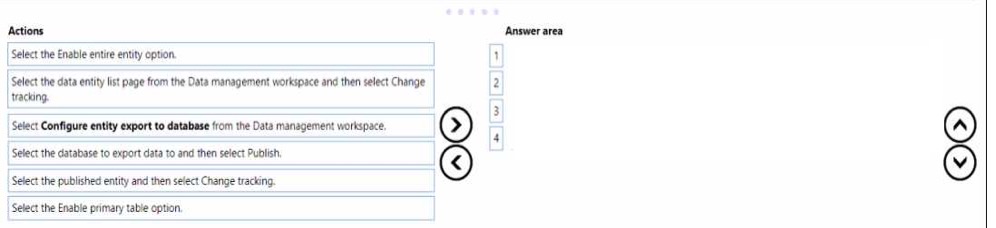
to join the discussion
No discussions yet. Be the first to ask!
Delete Comment
Are you sure? This action cannot be undone.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
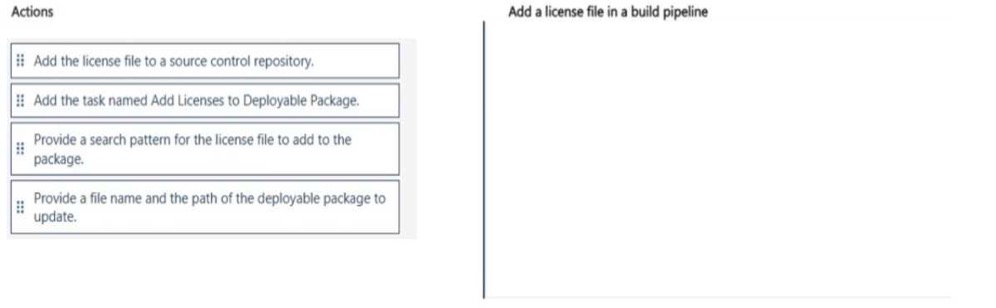
to join the discussion
No discussions yet. Be the first to ask!
Delete Comment
Are you sure? This action cannot be undone.
Finish Practice?
Are you sure you want to finish? This will end your practice session.